替换策略与分块技术
Cache运行与冲突替换
Cache运行流程
如下图所示,当我们对一个地址进行访存操作时,我们按照前文所述的地址结构进行匹配。
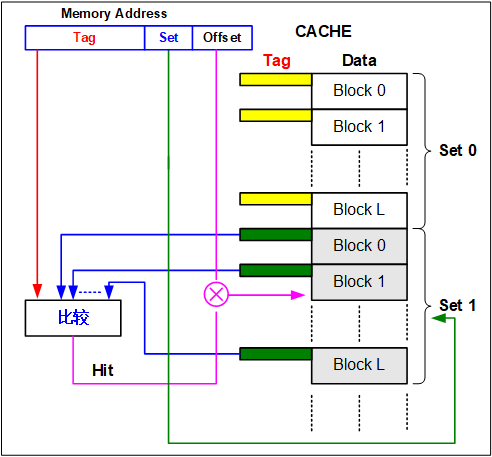
首先我们根据地址中的组号(set),查找到Cache中的对应组(图中绿色箭头所指的部分)。之后我们将标记(tag)与Cache中该组所有行的tag进行比较(即图中左部比较的部分)。
如果Cache中某行的tag能够匹配,则说明Cache中有对应的数据块,即命中(hit)。当命中时,处理器直接对Cache进行对应的访存操作,可以通过地址中的offset,查找Cache存储的block中的offset,从而找到该地址对应的数据信息。
如果Cache中没有对应的数据块,那么就是不命中(miss)的情况。当不命中时,缓存从主存中取出包含该地址的块,并需要放入缓存中。假如Cache中该地址所属组的所有行均已被占用,那么就需要覆盖一个现有的块,这一过程通常称为替换/驱逐(eviction)。在本实验中,我们假设当Cache的块被换出时,被换出块中如果发生数据更改则此时写回主存。
这里我们就会遇到一个问题,当需要替换时,如何在Cache中选择被替换的块?我们的目的是使得发生替换的情况尽可能少,从理论上来说,我们应当选择现有块中将来不再使用的块,或者选择现有块中经过最长时间才会使用到的块,因为这最大程度上推迟了下一次发生替换的时刻,我们可以证明,如果我们能够预知程序未来将要访问的地址的话,上述的替换策略是最优的,这一策略被称为最佳置换算法(OPT,OPTimal selection)。
事实上,我们很难达到预知未来的要求,我们的替换选择往往通过已有的命中情况来推算,因此我们介绍以下三种常见的替换算法。
常见替换算法
先进先出法(FIFO,First-In-First-Out),顾名思义,即选择最早装入的块进行替换。它的实现比较简单,不需要记录各个块的访问情况,比较容易实现,开销小。但是这种算法没有依据访存的局部性原理(最早调入的块有可能是经常访问的块),因此不能提高Cache的命中率。
FIFO策略的实现:
- 缓存的每一块都设定一个计数器,初始时均为0。
- 当某块被装入或被替换时该块的计数器清为0,而同组的其它各块的计数器均加1,
- 当需要替换时就选择计数值最大的块被替换掉。
最低使用频率法(LFU,Least-Frequently Used),即替换出使用频率最低的块,又称最不经常使用算法。
LFU策略的实现:
- 缓存的每一块都设定一个计数器,初始时均为0。
- 当某块被装入或被访问时该块的计数器加1。
- 当需要替换时就选择计数值最小的块被替换掉,如果计数值相同则替换出装入时间更早的块。
最近最少使用法(LRU,Least-Recently Used),含义为替换出近期用的最少的块。它与LFU的区别在于它更加关注各个块在近期的访问情况,即近期的权重会更高。LRU需要随时记录Cache中各块的访问情况,以便确定近期最少使用的块。LRU比较复杂,一般来说我们采用简化的方法,只记录每个块最近一次使用的时间,替换时选择距上一次使用经过时间最长的块。
LRU策略的实现:
- 缓存的每一块都设置一个计数器,初始时均为0。
- 访问命中时,所有块的计数值与命中块的计数值进行比较,如果某块计数值小于命中块的计数值, 则该块的计数值加 1;如果该块的计数值大于命中块的计数值,则数值不变;最后将命中块的计数器清为0。
- 访问未命中,需要替换/装入时,则选择计数值最大的块被替换/装入,其计数器清为0,而其它的计数器则加1(除了初始装入之外,计数值是不会出现相等情况的,可以思考一下为什么)。
分块技术与实验提示
分块技术
分块技术是一项很有趣的技术,它可以提高循环中的时间局部性。分块的大致思想是将一个程序中的数据结构组织成大的块(在这里,“块”指的是一个应用级的数据组块,而不是我们之前介绍的高速缓存块)。这样构造程序,使得能够将一个块加载到高速缓存中,并在这个块内进行所需的所有读和写,然后丢掉这个块再加载下一个块。
分块会使得代码更难阅读和理解,由于这个原因,它最适合优化编译器或者频繁执行的库函数。这项技术学习和理解起来还是很有趣的,因为它是一个通用的概念,可以在一些系统上获得极大的性能收益。
实验提示
我们将以 $s=5,E=1,b=5$ 结构的Cache为例,结合大小为 $32\times 32$ 的矩阵,来初步分析在矩阵转置中应用分块等技术可以优化的方面,希望能够启发同学们的思路。我们假设矩阵A和B的地址都是block大小对齐的。
最常规的转置思路即,遍历A的所有行,将其存放到B的对应列中。
void trans(int M, int N, int A[N][M], int B[M][N])
{
int i, j;
for (i = 0; i < N; i++) {
for (j = 0; j < M; j++) {
B[j][i] = A[i][j];
}
}
}
我们来结合Cache的结构分析一下转置过程中产生的缺失(miss)情况。首先block大小 $B=2^b=32$ 字节,即可以存放 $8$ 个int型值;$E = 1$ 为直接映射,即Cache中每组只有一行;$S = 2^s=32$ ,即分为 $32$ 个组,整个Cache可以存放 $32\times 8=256$ 个int型值。对应到矩阵中,我们可以发现,矩阵的前8行就正好能够填满我们的Cache。结合下方矩阵B的示意图,我们可以进行进一步的分析。
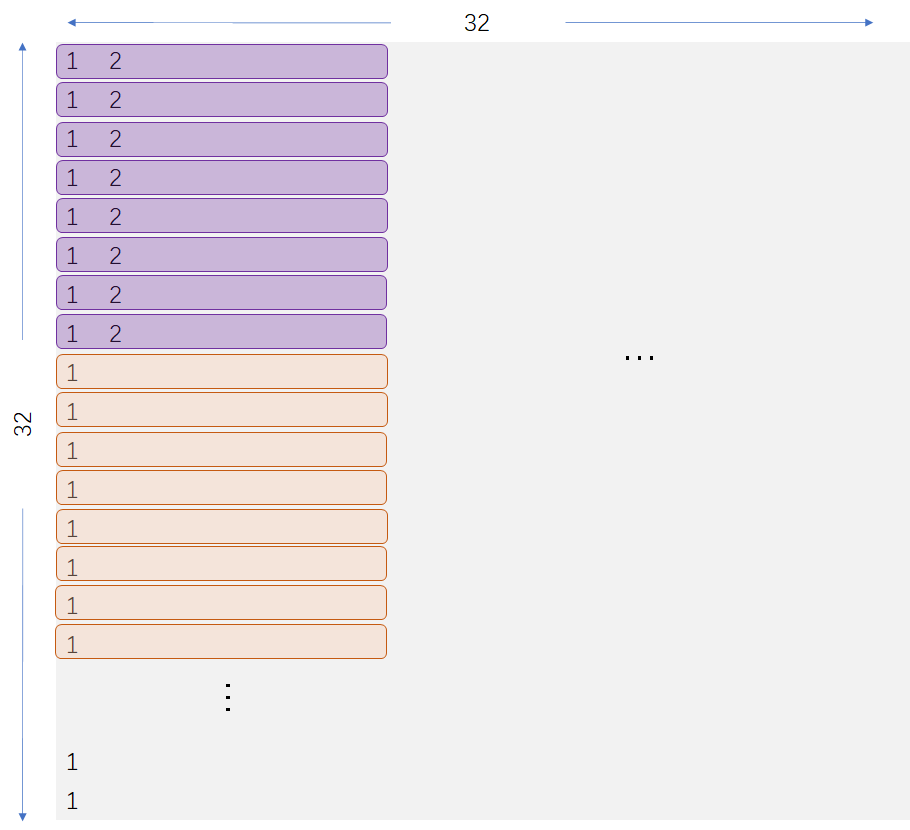
当我们填充B的第一列时,我们首先填充第一列的前8个位置,尽管我们每行只填一个值,但是Cache将一次性地把整个block都装入(图中的紫色块),这对应了8个int的大小。当我们填充第一列的第9个位置时,我们会发现它与第1个位置之间正好差了256个int值,这也就意味着将它对应的block装入Cache需要换出第1个位置的block(也即图中的红色块将替换图中的紫色块)。
当填充完第一列的第9-16个位置时,在Cache中红色块已经完全地替代了紫色块。继续下去,当填完第一列时,上述历程已经经历了4轮,并产生了32个miss。下面我们开始填充第二列的第1-8个位置,我们需要的值仍然落在紫色块中,我们发现此前装入的紫色块已经被换出,因此我们又要重新装入这些块,当我们填完第二列时,我们又会产生32个miss。如此下去我们会发现,当我们每填1个新的值,我们就会产生1个miss,这也就是这一情况下转置算法需要优化的原因。
究其根本,我们会发现矩阵的地址中,每8行就对应遍历一遍Cache,当超过8行之后,对应位置之前装入的块就会被替换。由此我们可以得到 $8\times 8$ 分块的解决思路,我们将 $32\times 32$ 的矩阵划分成 $16$ 个 $8\times8$ 子块,当对一个子块完成转置之后再转置下一个子块。
在一个子块内,当我们填完第一列的8个位置后,我们紧接着填第二列的8个位置,这时所有的块都会包含在Cache中,因此填第二列时都会命中,同样从第3列到第8列也都会命中,也即平均每填8个值才会产生一次miss,从而优化了算法。
但是我们以上的分析仅仅考虑了向B中写入值的情况,我们还没有分析从A中取值所产生的miss,也没有考虑矩阵A和矩阵B之间数据块相互替换的情况(在实验代码中,A和B的起始地址间隔保证了是Cache容量的整倍数,也就是说A对应位置的换入会导致B对应位置的换出,基于这一点又会多出额外的miss)。理论分析可知,在本例中从A中读入和向B中写入最少都需要各自产生128次miss(每个block在第一次读和写的时候肯定都是不命中的),因此指导我们优化的目标就是256次miss这一上界,基于此大家可以思考进一步如何优化转置算法,这对完成我们实验中的题目也会有极大启发。
以上的例子简单地介绍了最基本的优化思路,在实验题目的Part2中,我们需要依据给出的Cache结构和矩阵大小进行类似的分析,在最基本的分块上做一些进一步的优化,从而达到课下实验的通过要求。